
Machine learning projects depend heavily on the quality and reliability of data and model pipelines. Yet many organizations struggle to maintain clean, efficient, and reliable pipelines, leading to model drift, brittle deployments, and delayed insights. For employers looking to succeed with machine learning initiatives, understanding how to enable your ML engineers through pipeline hygiene is crucial. How can you help your team establish robust data and model pipeline hygiene practices that ensure consistent performance, reduce downtime, and accelerate innovation?
This operator playbook offers a detailed step-by-step methodology ML engineers can implement to maintain exemplary pipeline hygiene. By adopting these best practices, employers empowering teams who hire ML developers or hire dedicated ML developers will ensure resilient and scalable AI systems. We present actionable tactics grounded in industry standards, research, and practical experience for data cleaning, validation, model versioning, testing, monitoring, and lifecycle maintenance. Additionally, a practical template at the end standardizes hygiene workflows, empowering teams and simplifying oversight.
1. Understanding Pipeline Hygiene in Machine Learning
Pipeline hygiene refers to systematic practices that keep data and model pipelines clean, validated, monitored, and version-controlled across the ML lifecycle. Clean pipelines reduce errors caused by data inconsistencies, improve model reproducibility, and ensure stable production outcomes.
Well-maintained pipelines integrate continuous checks and balances from raw data ingestion to model deployment and monitoring. Pipeline hygiene is critical for organizations that hire machine learning developers or hire dedicated machine learning developers to accelerate value delivery without compromising reliability.
2. Cleaning and Validating Data Inputs
The foundation of any robust ML pipeline is high-quality, trustworthy data. Implementing stringent hygiene here reduces bias, data drift, and unexpected model behavior downstream. Follow these steps:
a. Data Profiling and Initial Cleaning
- Conduct exploratory data analysis to understand distributions, detect missing values, outliers, and anomalies. Tools such as Pandas Profiling or DataProfiler can automate this step.
- Clean data systematically by filling or imputing missing values, removing duplicates, and addressing corrupted records.
- Enforce schema validation using systems like Apache Avro or TensorFlow Data Validation (TFDV) to ensure incoming data conforms to expected types and ranges.
b. Automate Data Validation and Anomaly Detection
- Implement automated checks for statistical property shifts in features (e.g., mean, variance) through tools like Great Expectations or TFX.
- Set alert thresholds early to detect data drift before models degrade in production, as recommended by Google’s AI Principles and Best Practices.
- Maintain detailed logs of validation outcomes to track recurring data quality issues over time.
3. Versioning Data and Models
Version control is fundamental to traceability and rollback capability. This helps teams identify which data versions relate to trained models, essential for diagnosing performance issues.
- Use platforms like DVC (Data Version Control) or Pachyderm to version datasets alongside code.
- Employ model registries such as MLflow or Seldon Core to track model versions, associated metrics, and metadata.
- Maintain linkage between dataset versions and model builds explicitly using unique hashes or identifiers.
4. Testing Machine Learning Models
Testing ML models differs from traditional software testing but is equally important for hygiene.
- Implement unit tests for preprocessing functions, feature engineering pipelines, and model components.
- Use integration tests that validate the entire pipeline from raw data to prediction outcomes. Tests should verify input/output shapes, ranges, and handle edge cases.
- Perform validation on holdout datasets, monitoring key metrics like accuracy, F1 score, and calibration regularly.
- Automate testing workflows as part of CI/CD pipelines using tools like Jenkins or GitLab CI, ensuring prompt feedback on model quality in pre-production stages.
5. Monitoring Models in Production
Continuous monitoring is the final guardrail to maintain pipeline health long-term.
- Track data quality metrics in production using feature stores or monitoring platforms such as Evidently AI or Fiddler Labs.
- Monitor predictions for distributional changes and performance degradation using model monitoring dashboards.
- Set up anomaly detection alerts to notify ML engineers proactively about unexpected drift or performance dips.
- Conduct regular model re-training triggered by drift detection or schedule-based triggers to keep models current.
6. Maintaining and Updating Pipelines
Pipeline hygiene also requires proactive maintenance strategies:
- Periodically audit pipeline components for outdated dependencies or deprecated APIs.
- Conduct retrospective reviews post-deployment to capture lessons from pipeline failures or data incidents.
- Leverage containerization and orchestration (e.g., Docker and Kubernetes) to standardize environments and minimize “works on my machine” issues.
- Document workflows clearly and maintain runbooks for troubleshooting known pipeline failure modes.
7. Actionable Tactics to Identify and Resolve Pipeline Issues Before Production Impact
To prevent costly failures, integrate these tactics:
- Develop pre-deployment checks that validate new data batches and model versions automatically.
- Use synthetic testing data to simulate edge cases or stress test models before release.
- Create cross-functional feedback loops among data engineers, ML developers, and business stakeholders for rapid issue detection and resolution.
- Employ root cause analysis frameworks such as the “5 Whys” or Ishikawa diagrams to diagnose pipeline disruptions methodically.
- Schedule regular ‘pipeline dry runs’ where your team simulates the full workflow under controlled conditions.
Practical Pipeline Hygiene Workflow Template for ML Engineers
To standardize hygiene workflows, here is a simple checklist template ML engineers can adapt:
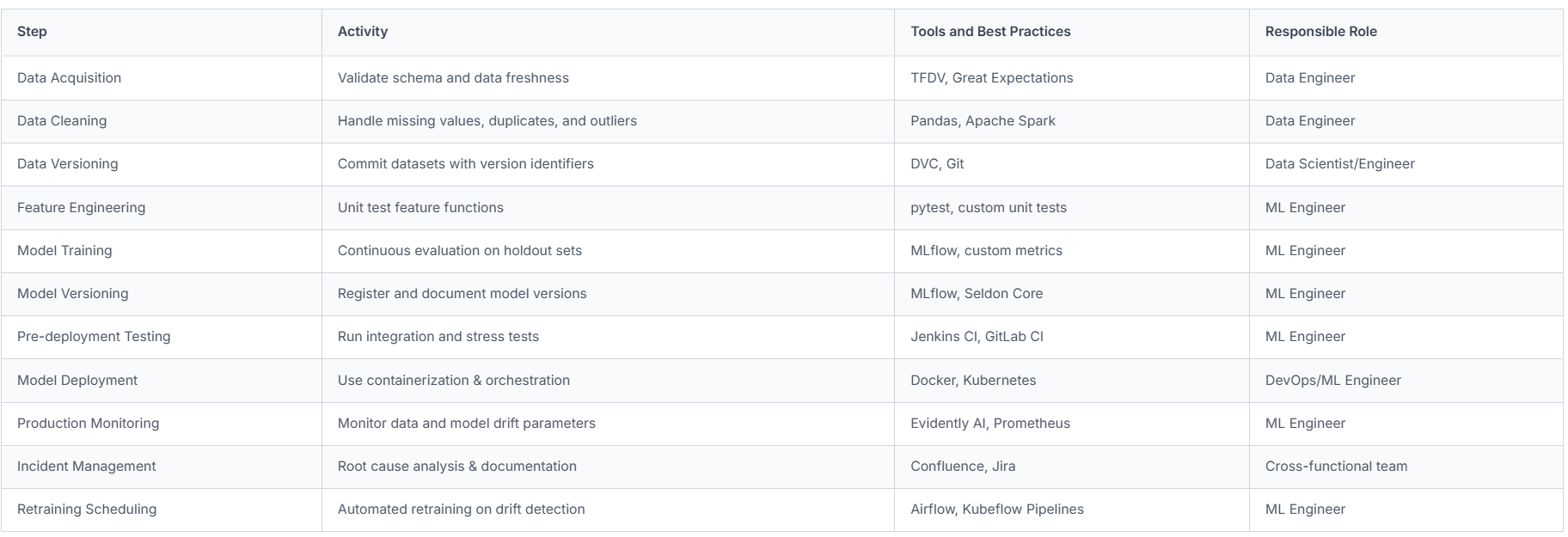
Final Notes for Employers: Supporting Your ML Team’s Hygiene Efforts
Employers who hire dedicated ML developers need to invest not only in talent but also in robust infrastructure, tools, and training to foster pipeline hygiene culture. Clear communication of hygiene standards, involvement in cross-team collaboration, and recognizing the technical debt caused by neglected pipelines will improve outcomes.
When you hire ML developer talent, emphasize that hygiene operations form a core part of their workflow, not an afterthought. This mindset translates to faster deployments, reliable models, and ultimately to business impact.
Employing dedicated machine learning developers with a strong focus on hygiene paired with mature processes gives you a competitive advantage by safeguarding your AI investments from costly regressions and operational risks.
Employers ready to unlock the full potential of their machine learning projects should make pipeline hygiene a strategic priority. Supporting your ML engineers with detailed methodologies, process templates, and environment tools paves the way for sustained AI excellence.
By adopting the comprehensive pipeline hygiene best practices outlined here, you can confidently hire ML developers or hire dedicated ML developers who not only build models but deliver trusted, maintainable, and scalable ML systems.
References
- Google AI Best Practices: https://ai.google/education
- TensorFlow Data Validation: https://www.tensorflow.org/tfx/data_validation
- Great Expectations Documentation: https://greatexpectations.io/
- MLflow for Model Management: https://mlflow.org/
- Evidently AI for Monitoring: https://evidentlyai.com/
- DVC (Data Version Control): https://dvc.org/
- Seldon Core: https://www.seldon.io/
- Airflow for Orchestration: https://airflow.apache.org/
By following this guide, employers gaining leadership over machine learning development pipelines can ensure their teams succeed in maintaining high pipeline hygiene standards, turning complexity into streamlined operational excellence."

